
Concurrency in Go Feels More Like Organizing People Than Using Threads
A human way to understand go-routines, scheduling, and work stealing

Before talking about go-routines, channels, or worker pools, we must ask a basic question:
Can this problem be solved serially in a simple, obvious way?
Take the counting problem.
Count from 1 to 10,000
A single loop does this perfectly fine.
Easy to read
Easy to reason about
Zero coordination cost
No overhead
If your program only needs to count 10,000 numbers, introducing concurrency would be like hiring 8 people to count 10 pages — you’d spend more time coordinating than counting.
This way of thinking applies not just to abstract numbers, but to how humans naturally organize work at scale.
When Concurrency Becomes a Question
Now change the problem slightly:
Count from 1 to 1,000,000,000
Suddenly, the serial solution has a cost:
The CPU is busy for a long time
Other work might be blocked
The program becomes unavailable for extended periods
This is the key transition point.
We don’t introduce concurrency because the task is big.
We introduce concurrency because the serial execution makes something unavailable.
I realized that the problem of counting currency notes maps extremely well to how concurrency in Go — and even the Go scheduler — is designed.
If we think about the currency note counting problem, when there are only a few bundles, we don’t need to think much — a single person and a single counting table are more than sufficient.
But if we are supplied with a huge number of currency note bundles — say, suitcases full of them — counting alone no longer makes sense, even if the person is perfectly capable.
So the key takeaway here is this: unless the scale of the problem is large enough, we don’t need to jump into thinking in terms of concurrency.
Keeping that in mind, let’s understand concurrency design by co-relating it with the currency note counting problem.
Counting Hall Story
Deciding on the Cast
The hall has a limited number of counting tables (say 8).
The hall receives many currency note bundles of different denominations.
There are many people who know how to count notes — workers.
Condition: a worker can count only when they acquire both a table and a bundle.
Sometimes, we deliberately assign more workers than tables.
This ensures that tables never sit idle — if someone finishes early or pauses, another worker can immediately take the chair.
Even if a worker has been waiting near one table, they may notice another table becoming free and rush to occupy it.
In addition, we introduce two special roles:
Producers, who distribute bundles to workers
Accumulators, who collect and aggregate results
Deciding on the Implementation
Conceptually, the implementation consists of two pipes:
a job pipe
a result pipe
This separation ensures unidirectional flow and clear ownership of responsibilities.
Every worker is connected to:
the receiving end of the job pipe
when a worker acquires a table, they receive a currency bundle from this job pipe
the sending end of the result pipe
after counting the bundle, the worker prepares a result chit and sends it through the result pipe to the accumulator
The producer is connected to the sending end of the job pipe.
The accumulator is connected to the receiving end of the result pipe.
Co-relating with Go
The Corresponding Cast
If we map this to a Go implementation, the cast looks like this:
The machine has a limited number of CPU cores (say 8).
The machine maps to the hall and each CPU maps to table with chair
We have a set of note bundles of different denominations.
Each worker go-routine, when in the Running state, is capable of counting notes from a given bundle when assigned CPU time.
Each worker go-routine maps to a worker (human knowing counting)
Condition: a go-routine can count only when it is given both a CPU and a bundle.
The extra worker go-routines remain in the Runnable / Ready state — not counting yet, but ready to run and waiting near a CPU.
Conceptually, the behavior of acquiring the first available chair maps closely to Go’s work-stealing scheduler, where idle processors pull runnable go-routines from other queues to keep CPUs busy.
Can read more about work-stealing in Go’s scheduler here.
The producer and accumulator go-routines are special go-routines that do not count notes themselves, but instead facilitate work (bundle) distribution and result aggregation.
The Corresponding Implementation
The pipes are implemented using Go channels.
Now, if we look at the following Go implementation, the analogy becomes much clearer.
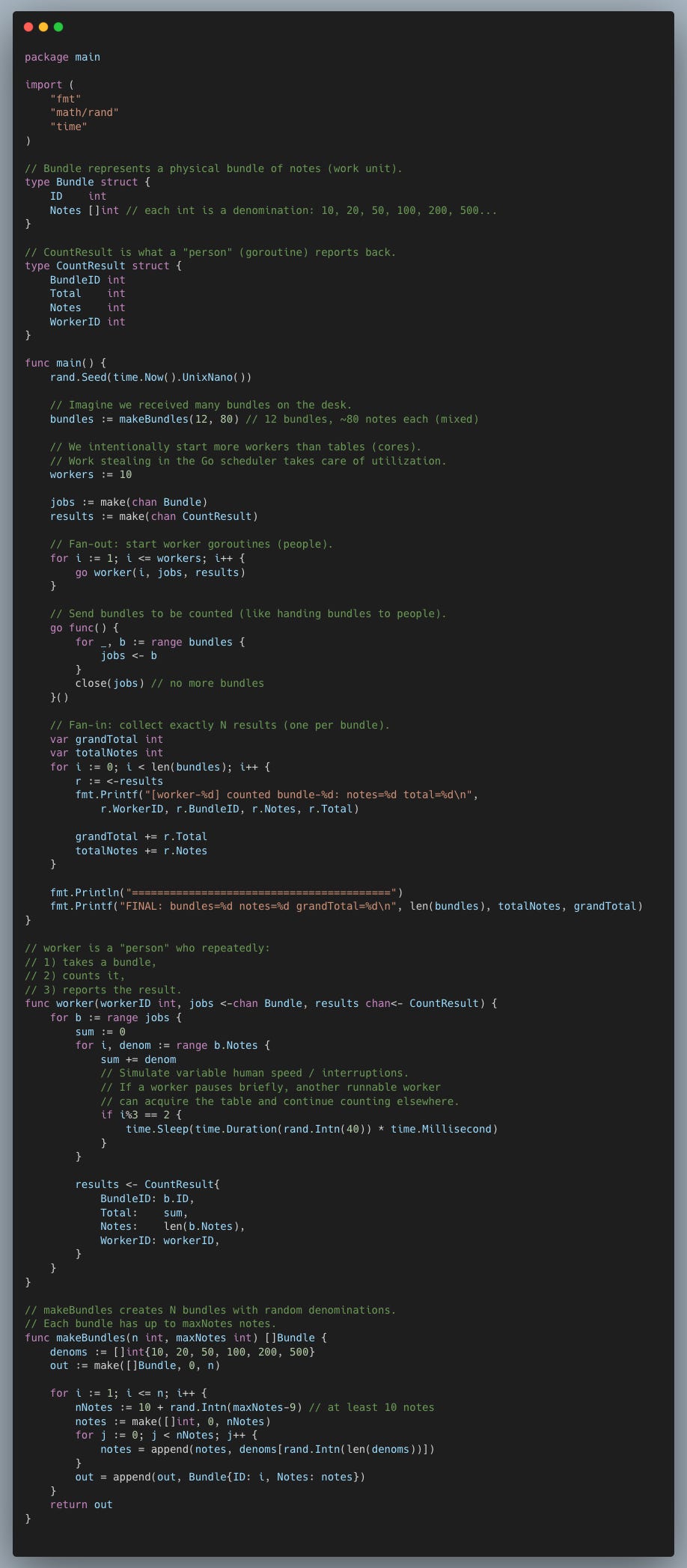
Output
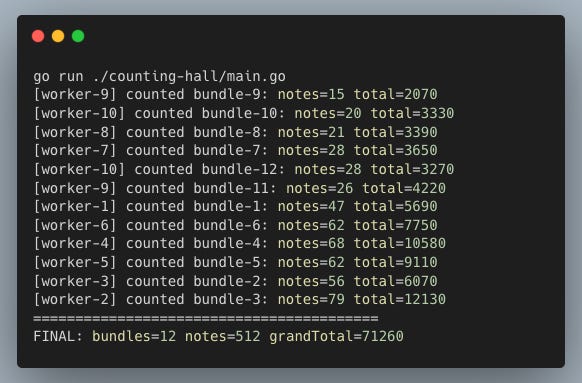
Co-relation
Each worker go-routine counts a bundle of notes received through the jobs channel (pipe) from the producer go-routine and sends the result through the results channel (pipe).
This behavior is enforced by the signature of the
workerfunction:jobsparameter has the type<-chan Bundle, a read-only channel, which explicitly restricts the worker to only receiving from thejobschannel and not sending into it.resultsparameter has the typechan<- CountResult, a send-only channel, which explicitly restricts the worker to only sending results into theresultschannel and not receiving from it.
This makes the worker’s role unambiguous: it consumes work from one pipe and produces results into another.
The main go-routine acts as the accumulator, holding the receiving end of the results channel, into which all worker go-routines send their results.
Each CPU core acts as a counting table.
The
[]Bundle{}slice represents the collection of bundles to be counted.CountResultrepresents the result chit prepared by each worker and sent through the results channel (pipe) to the accumulator.
Conclusion
In the end, I don’t want us to lose sight of the availability over speed perspective on concurrency.
Throughout the counting hall story, the goal was never to make a single person count faster.
The goal was to make sure that counting never stops.
We added more workers not to increase individual speed, but to ensure that:
when one worker pauses, another can immediately take a table,
when one table becomes free, some worker is always ready to occupy it,
and no table ever sits idle while work is waiting.
That is exactly what Go’s concurrency model optimizes for.
Go-routines are cheap to create not so that they all run at once, but so that there is always work ready when CPU time becomes available.
Runnable go-routines exist so that the system can immediately make progress when capacity frees up.
Work stealing exists so that idle CPUs don’t wait while work is stuck elsewhere.
All of this is about keeping the system responsive and productive, even as the amount of work scales.
That brings us back to the core idea:
Concurrency is not about making one person faster.
It’s about keeping the hall productive even when work scales.
And that, more than raw performance, is what good concurrency design is about.
At its core, good concurrency prioritizes:
availability — the system is always ready to do useful work,
clarity — each component has a well-defined role,
structure — work flows in one direction with clear coordination,
and human-like organization — because that’s how large systems naturally scale.