
I Thought Connection Pooling Was About Caching. It's About Framing Protocols and Synchronization Knobs.
Why knowing when a response ends is only half the problem — the other half is controlling bursts, memory, and server load with semaphores and mutexes?

A while back I wrote about Go’s netpoller and the full lifecycle of a TCP connection. You can read it here. It ended with:
While Go’s netpoller solves thread efficiency, pools address the underlying connection cost problem.
That closing line sat with me for days. I understood the netpoller, the kernel queues, the handshake, pollDesc, epoll. But I had no concrete picture of what a pool actually is or how it decides when a connection is safe to reuse.
So I built one from scratch. Raw TCP, no frameworks, just net.Dial, net.Listen, and the same connection lifecycle I mapped in the previous article.
This is what I found.
Connection Pooling Starts with a Server Decision
The first thing that surprised me: connection pooling is not a client invention. It requires an explicit server choice.
A naive server closes after every response:
conn, _ := listener.Accept()
handleRequest(conn)
conn.Close() // connection dead
This is what I built first. Clean, simple, and expensive. Every new request pays the full cost again: TCP handshake (SYN, SYN-ACK, ACK), buffer allocation, pollDesc registration, the whole setup.
A pooling-aware server does the opposite. It stays in a loop:
conn, _ := listener.Accept()
sc := bufio.NewScanner(conn)
for sc.Scan() {
handleRequest(sc.Text())
fmt.Fprintf(conn, "response\n")
}
// loop only exits when client disconnects or idle timeout fires
The for sc.Scan() is the deliberate decision. The server goroutine stays parked on the netpoller between requests, no OS thread consumed, connection held open. This is what gives the client something to reuse.
By not closing, the server lets the client leverage pooling. The benefit runs both ways: client avoids the handshake cost, server reuses its own goroutine instead of spawning new ones per connection.
The Framing Contract
The server staying in the loop creates a fundamental problem. How does it know where one request ends and the next begins?
The client writes:
request1\nrequest2\nrequest3\n
The server’s sc.Scan() uses \n as the boundary. It reads until it hits the delimiter, then stops. Real databases use length-prefixed frames or special terminator bytes. Same idea, different encoding.
But there’s a second problem. How does the client know when the full response has arrived and it’s safe to return the connection to the pool?
Return the connection mid-response and the next caller gets a connection with leftover bytes in the recv buffer. Corrupted data.
How different systems solve this:
Postgres: sends
CommandComplete+ReadyForQueryframes.ReadyForQuerymeans “full response delivered, connection is idle.”HTTP chunked:
0\r\nterminating chunk signals “stream over.”HTTP with Content-Length: client reads exactly N bytes, done.
Pooling and framing are inseparable. Without the sentinel, the pool can’t know when a connection is safe to reuse. This is why database drivers and HTTP clients always implement a framing protocol alongside the pool. They’re two halves of the same contract.
Building the Simplest Pool
I started with a buffered channel:
type ConnPool struct {
pool chan net.Conn // capacity = MaxConn
Addr string
}
func (p *ConnPool) GetConn() (net.Conn, error) {
select {
case conn := <-p.pool:
return conn, nil
default:
return net.Dial("tcp", p.Addr)
}
}
func (p *ConnPool) ReturnConn(c net.Conn) {
select {
case p.pool <- c:
default:
c.Close() // pool full, close to avoid fd leak
}
}
The default case in both is key. In GetConn: pool empty, dial fresh. In ReturnConn: pool full, close the connection. Not drop, close. Dropping it leaks the fd and kernel socket struct.
A buffered channel is the synchronization primitive. No mutex needed, channels are already thread-safe.
I ran this with a pool size of 3 and created 5 connections. The first 3 went into the pool. The 4th and 5th hit the default case in ReturnConn and were closed immediately.
The proof of reuse: same ephemeral port.
iter[0]: conn.LocalAddress(127.0.0.1:55645)
iter[1]: conn.LocalAddress(127.0.0.1:55645) ← same port
The kernel assigns one ephemeral port per TCP connection. Same port across two GetConn calls = same net.Conn returned from pool = zero new dials.
The Overflow Demo
I wanted to see what happens when more connections are created than the pool can hold.
Setup: pool size = 3, MaxConn = 3. I created 5 connections total. The first 3 should go into the pool. The last 2 should hit the default case in ReturnConn and be closed immediately.
The code:
pool := pool.New(":4040")
// grab 2 extra connections before warming pool
conn3, _ := pool.GetConn()
conn4, _ := pool.GetConn()
// warm up pool with 3 connections
conns := []net.Conn{}
for i := 0; i < 3; i++ {
conn, _ := pool.GetConn()
conns = append(conns, conn)
}
for _, conn := range conns {
pool.ReturnConn(conn) // pool now full: 3 connections
}
// first loop: grab from pool, use, return
for i := 0; i < 3; i++ {
conn, _ := pool.GetConn()
handleConn(i, conn, pool) // i = 0, 1, 2
}
// second loop: same 3 connections reused
for i := 0; i < 3; i++ {
conn, _ := pool.GetConn()
handleConn(i, conn, pool) // i = 0, 1, 2 again
}
// overflow: these two hit pool full → closed
handleConn(3, conn3, pool)
handleConn(4, conn4, pool)
Each handleConn writes one line with the iteration number i, reads the echo response, calls ReturnConn:
func handleConn(i int, conn net.Conn, pool *pool.ConnPool) {
fmt.Printf("iter[%d]: conn.LocalAddress(%v)\n", i, conn.LocalAddr())
fmt.Fprintf(conn, "[%d]: hi\n", i) // writes "[0]: hi\n" or "[1]: hi\n"
sc := bufio.NewScanner(conn)
sc.Scan()
fmt.Println(sc.Text())
pool.ReturnConn(conn)
}
The [0], [1], [2] in the logs are the iteration numbers from the loops. They’re not goroutine IDs (the server is single-threaded in the client, looping sequentially). The server echoes back whatever it receives, so [0]: hi in the request becomes [0]: hi in the response.
Server-side code:
listener, _ := net.Listen("tcp", ":4040")
i := 0
for {
conn, _ := listener.Accept()
go func(conn net.Conn, gri int) {
defer conn.Close()
sc := bufio.NewScanner(conn)
who := conn.RemoteAddr()
log.Printf("[go-routine-%d][%s]: connected\n", gri, who)
for sc.Scan() {
t := sc.Text()
log.Printf("[go-routine-%d][%s]: %s\n", gri, who, t)
fmt.Fprintf(conn, "[go-routine-%d]echo: %s\n", gri, t) // echo back
}
log.Printf("[go-routine-%d][%s]: disconnected\n", gri, who)
}(conn, i)
i++
}
The gri (goroutine ID) is just an incrementing counter captured at Accept() time. Each new connection gets the next number. The server stays in the for sc.Scan() loop, handling multiple requests on the same connection until the client disconnects or the connection is closed.
Client logs showed this:
iter[0]: conn.LocalAddress(127.0.0.1:55645)
[go-routine-2]echo: [0]: hi
iter[1]: conn.LocalAddress(127.0.0.1:55646)
[go-routine-3]echo: [1]: hi
iter[2]: conn.LocalAddress(127.0.0.1:55647)
[go-routine-4]echo: [2]: hi
iter[0]: conn.LocalAddress(127.0.0.1:55645) ← same port, reused
[go-routine-2]echo: [0]: hi
iter[1]: conn.LocalAddress(127.0.0.1:55646) ← same port, reused
[go-routine-3]echo: [1]: hi
iter[2]: conn.LocalAddress(127.0.0.1:55647) ← same port, reused
[go-routine-4]echo: [2]: hi
iter[3]: conn.LocalAddress(127.0.0.1:55643) ← overflow connection
[go-routine-0]echo: [3]: hi
iter[4]: conn.LocalAddress(127.0.0.1:55644) ← overflow connection
[go-routine-1]echo: [4]: hi
Server logs showed this:
[go-routine-0][127.0.0.1:55643]: connected
[go-routine-1][127.0.0.1:55644]: connected
[go-routine-2][127.0.0.1:55645]: connected
[go-routine-3][127.0.0.1:55646]: connected
[go-routine-4][127.0.0.1:55647]: connected
[go-routine-2][127.0.0.1:55645]: [0]: hi
[go-routine-3][127.0.0.1:55646]: [1]: hi
[go-routine-4][127.0.0.1:55647]: [2]: hi
[go-routine-2][127.0.0.1:55645]: [0]: hi ← same goroutine, second request
[go-routine-3][127.0.0.1:55646]: [1]: hi ← same goroutine, second request
[go-routine-4][127.0.0.1:55647]: [2]: hi ← same goroutine, second request
[go-routine-0][127.0.0.1:55643]: [3]: hi
[go-routine-0][127.0.0.1:55643]: disconnected ← immediately, pool full
[go-routine-1][127.0.0.1:55644]: [4]: hi
[go-routine-1][127.0.0.1:55644]: disconnected ← immediately, pool full
[go-routine-4][127.0.0.1:55647]: disconnected ← on process exit
[go-routine-2][127.0.0.1:55645]: disconnected ← on process exit
[go-routine-3][127.0.0.1:55646]: disconnected ← on process exit
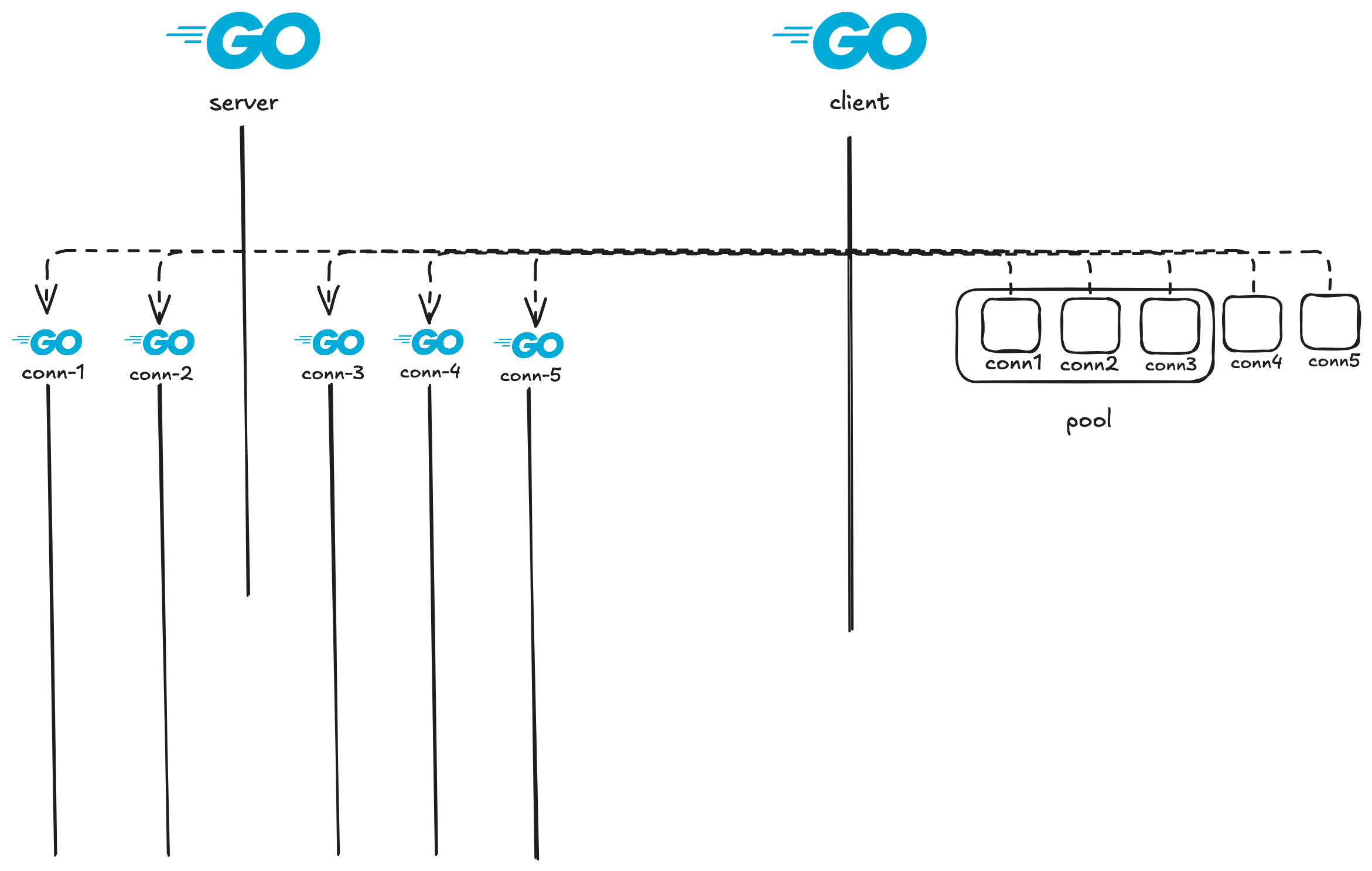
Reading the logs step by step:
Initial dial (5 connections created):
Ports 55643, 55644 — the two overflow connections (
conn3,conn4)Ports 55645, 55646, 55647 — the three warm-up connections, returned to pool
First loop (iter 0, 1, 2):
Client grabbed ports 55645, 55646, 55647 from pool
Same ports = same
net.Conn= zero new dialsServer: go-routine-2, 3, 4 handle these requests
Client returns all 3 to pool after use
Second loop (iter 0, 1, 2 again):
Client grabbed the same three ports again from pool
Server: go-routine-2, 3, 4 handle their second request on the same connection
This is connection reuse in action: same goroutine, same connection, two separate request-response cycles
Client returns all 3 to pool again
Overflow (iter 3, 4):
Client calls
handleConn(3, conn3, pool)andhandleConn(4, conn4, pool)Both write their request, get a response, call
ReturnConnPool is already full (3/3)
ReturnConnhits thedefaultcase:c.Close()Server receives FIN on ports 55643 and 55644
go-routine-0 and go-routine-1 wake from
sc.Scan(), see EOF, loop exits“disconnected” logs fire immediately after handling the request
Process exit:
Client process exits
OS closes all remaining fds (55645, 55646, 55647)
FINs go out
go-routine-2, 3, 4 wake from
sc.Scan(), see EOF, disconnect
The key proof: go-routine-2 handled two requests on port 55645 (iter[0] in both loops). Same ephemeral port = same TCP connection = same kernel tcp_sock structure = zero new handshakes. The connection was returned to the pool after the first loop and grabbed again in the second loop.
go-routine-0 and go-routine-1 disconnected immediately because ReturnConn closed them, not because the server decided to. The pool was full, the default case fired, c.Close() sent a FIN.
Adding MaxConnsPerHost
A buffered channel pool has no burst protection. 1000 goroutines hitting GetConn simultaneously dial 1000 connections to the server at once.
Fix: a semaphore.
// pre-filled with MaxConnsPerHost tokens
maxConnsPerHost := make(chan struct{}, MaxConnsPerHost)
for i := 0; i < MaxConnsPerHost; i++ {
maxConnsPerHost <- struct{}{}
}
// GetConn: acquire token before dialing
<-p.MaxConnsPerHost // blocks when at limit, parks goroutine
// ReturnConn: release token when connection is closed
p.MaxConnsPerHost <- struct{}{}
chan struct{} not chan int. struct{} is zero-size, no allocation per token.
I ran 10 goroutines with MaxConnsPerHost=6:
02:26:36 [go-routine-6] blocking for MaxConnsPerHost ← 4 parked immediately
02:26:36 [go-routine-7] blocking for MaxConnsPerHost
02:26:36 [go-routine-8] blocking for MaxConnsPerHost
02:26:36 [go-routine-4] blocking for MaxConnsPerHost
02:26:36 [go-routine-1] using conn.LocalAddress(127.0.0.1:58963) ← 6 dial
02:26:36 [go-routine-3] using conn.LocalAddress(127.0.0.1:58964)
02:26:36 [go-routine-2] using conn.LocalAddress(127.0.0.1:58966)
02:26:36 [go-routine-5] using conn.LocalAddress(127.0.0.1:58967)
02:26:36 [go-routine-0] using conn.LocalAddress(127.0.0.1:58965)
02:26:36 [go-routine-9] using conn.LocalAddress(127.0.0.1:58968)
← 2 seconds later
02:26:38 [go-routine-6] using conn.LocalAddress(127.0.0.1:58971) ← 3 unblock
02:26:38 [go-routine-8] using conn.LocalAddress(127.0.0.1:58970)
02:26:38 [go-routine-7] using conn.LocalAddress(127.0.0.1:58969)
Wave pattern: burst hits cap, excess goroutines park on the semaphore. As in-flight connections complete and return, parked goroutines unblock in waves.
IdleConnTimeout
Idle connections sitting forever create a problem: servers close them after their own timeout, sending a FIN. Client grabs the stale connection, writes a request, gets an error.
Fix: timestamp each connection on return. A background goroutine wakes periodically and evicts connections that have been idle too long.
type ConnPool struct {
mu sync.Mutex
pool []struct {
idleSince time.Time
conn net.Conn
}
MaxIdleConnsPerHost int
MaxConnsPerHost chan struct{}
IdleConnTimeout time.Duration
}
Why switch from channel to slice: a buffered channel can’t be peeked without consuming. To check expiry, you need to inspect elements without removing them. A slice as a FIFO queue works: append at the back (newest last), pop from back for GetConn (warmest first), check the front for eviction (oldest first).
Eviction interval: IdleConnTimeout / 2. Worst case: connection becomes idle just after a wakeup. One interval later it’s checked, age is IdleConnTimeout / 2. One more interval, evicted. Maximum overshoot: one interval. Go’s net/http uses exactly this internally.
I set IdleConnTimeout = 5 seconds for testing. After the client exited, the eviction goroutine woke 5 seconds later:
2026/05/10 00:32:04 [pool-idle-conn-eviction] closing conn: 127.0.0.1:57050
2026/05/10 00:32:04 [pool-idle-conn-eviction] closing conn: 127.0.0.1:57051
2026/05/10 00:32:04 [pool-idle-conn-eviction] closing conn: 127.0.0.1:57052
Server logs confirmed all 3 goroutines woke from sc.Scan() and disconnected at the same timestamp. The eviction goroutine freed them, not process shutdown.
Always set IdleConnTimeout below the server’s timeout. If the server times out first and sends a FIN, the client’s next attempt on that stale connection will error.
Dedicated-Host vs Shared-Host
The pool I built so far has Addr string hardcoded at construction. One pool per target server. This is a dedicated-host pool.
All knobs (MaxIdleConnsPerHost, MaxConnsPerHost, IdleConnTimeout) scope naturally to that one host. Simple, predictable.
A shared-host pool, one pool instance for all hosts, needs different structure. The flat slice becomes a map:
pool map[string][]struct {
idleSince time.Time
conn net.Conn
}
MaxConnsPerHost becomes map[string] → chan struct{}, one independent semaphore per host.
Now two scopes appear:
MaxIdleConnsPerHost(per-host), caps stale idle accumulation on any one hostMaxIdleConns(global), caps total idle connections across all hosts
Without the global cap, a client talking to 50 hosts with MaxIdleConnsPerHost=10 could hold 500 idle fds, most unused.
The Semaphore Invariant
Three operations touch both semaphores (IdleConns global, MaxConns[addr] per-host). The core invariant:
tokens_in_IdleConns + connections_in_pool = MaxIdleConns (always)
Operation MaxConns[addr] IdleConns global Dial new conn consume 1 no change ReturnConn → pool no change consume 1 (entering idle) ReturnConn → per-host cap release 1 (closed) no change ReturnConn → global cap release 1 (closed) no change GetConn → pool hit no change release 1 (leaving idle) Eviction release 1 (closed) release 1 (leaving idle)
Eviction must release both. An evicted connection held a per-host slot (consumed at dial) and a global idle slot (consumed at ReturnConn). Releasing only one causes permanent token starvation.
The Knobs
http.Transport exposes the same knobs I built:
MaxIdleConnsPerHost, warm idle connections per host. Default: 2 (very conservative). First thing to tune under high load.MaxIdleConns, global ceiling across all hosts. Only relevant when onehttp.Clienttalks to multiple hosts.MaxConnsPerHost, hard ceiling on total connections (idle + in-use). When hit, new requests block waiting. Default: 0 (no limit).IdleConnTimeout, evict idle connections after this duration. Default: 0 (connections sit forever, vulnerable to server-side RST).
MaxConnsPerHost protects the server from being overwhelmed. Set it higher than MaxIdleConnsPerHost to absorb burst: extra connections created under load get closed on ReturnConn (pool already full), naturally draining back to the idle cap.
There’s no global MaxConns. A global connection limit across all hosts has no coherent meaning. Throttling connections to api.stripe.com because you have too many open to api.github.com protects neither server.
SQLAlchemy Mapping
I recently worked on Airflow where many parallel DAG tasks were connecting to Postgres simultaneously. The default config was throwing connection errors.
The fix was tuning two SQLAlchemy knobs:
AIRFLOW__DATABASE__SQL_ALCHEMY_POOL_SIZE: "20"
AIRFLOW__DATABASE__SQL_ALCHEMY_MAX_OVERFLOW: "20"
These map directly:
POOL_SIZE=MaxIdleConnsPerHost, idle connections kept readyMAX_OVERFLOW= extra connections allowed beyond pool sizeMaxConnsPerHost=POOL_SIZE + MAX_OVERFLOW= 40 total
Airflow defaults: POOL_SIZE = 5, MAX_OVERFLOW = 5, 10 total. Under parallel DAG execution that exhausts fast.
Same semaphore pattern, same wave behavior, different language.
HTTP Framing
HTTP is the same pool, with a self-describing framing protocol.
Raw TCP framing:
Request end:
\nResponse end: implicit, one line echoed back
Connection fate: server loop stays open
HTTP framing:
Request end:
\r\n\r\nafter headers +Content-LengthbytesResponse end:
Content-Lengthbytes read OR0\r\n\r\nin chunked encodingConnection fate:
Connectionheader decides
http.Transport is a shared-host pool. The same knobs map directly: MaxIdleConnsPerHost, MaxIdleConns, MaxConnsPerHost, IdleConnTimeout.
HTTP/1.1 default is keep-alive. Connection: close is the opt-out. Connection: keep-alive is redundant. I verified this by removing it from the server, nothing observable changed in pool behavior.
resp.Body.Close() is not optional. Without draining and closing the body, http.Transport doesn’t know the response is complete. The connection can’t be returned to the pool. It leaks.
HOL Blocking
HTTP/1.1 with keep-alive: one connection, one request in-flight at a time.
I built a server that sleeps 5 seconds when the request body is "slow". Sent 10 sequential requests: fast, fast, fast, fast, slow, fast, fast, fast, fast, fast.
22:54:46 ConnectStart → :53594 ← one dial, one connection
22:54:46 GotConn :53594 → fast ← instant
22:54:46 GotConn :53594 → fast
22:54:46 GotConn :53594 → fast
22:54:46 GotConn :53594 → fast
22:54:46 GotConn :53594 → [waiting] ← slow request holds the connection
22:54:51 response: slow ← 5 seconds later
22:54:51 GotConn :53594 → fast ← all unblock instantly
One slow request blocked five fast requests. Not because the server was busy but because they all shared one connection with no way to label which response belongs to which request.
The root cause: ordering without identity. The TCP byte stream has no per-request label. Responses must come back in the same order as requests. Fix: HTTP/2 adds a 31-bit stream ID to every frame. The receiver reassembles each response independently. One connection, N concurrent streams, no HOL at the application layer.
The pool design determines HOL exposure: one idle connection = full HOL, more connections = isolated per-connection, HTTP/2 = eliminated at app layer (TCP HOL remains).
What’s Still Open
I now understand what a connection pool is and how it decides when a connection is safe to reuse. The framing contract is inseparable from pooling. The knobs (MaxIdleConnsPerHost, MaxConnsPerHost, IdleConnTimeout) map directly between raw TCP pools and http.Transport.
What I still don’t understand well enough: how HTTP/2 multiplexing actually works at the frame level. I know it uses stream IDs, but I want to see the bytes on the wire. How QUIC eliminates TCP HOL blocking by implementing per-stream reliability over UDP. What the trade-offs are between dedicated-host pools (one per service) and shared-host pools in a microservice environment.
That’s where this goes next.